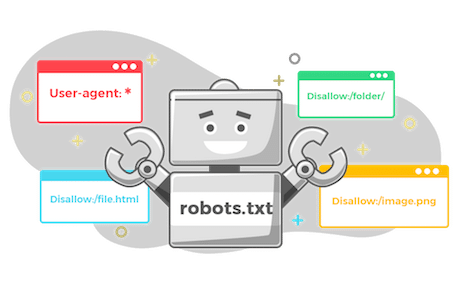
Robots.txt協(xié)議詳解及使用方法
robots.txt是一個簡單的文本文件,位于網(wǎng)站的根目錄下,用于告知搜索引擎爬蟲(如谷歌、百度等)哪些頁面或文件可以被爬取,哪些不可以。它使用了Robots Exclusion Standard(機器人排除標準)協(xié)議,是一種自愿遵守的網(wǎng)頁爬取規(guī)范。robots.txt的結(jié)構(gòu)及語法robots.txt文件主要包含兩個部分:User-agent(用戶代理)和Disallow(禁止)。User-age